How to create a heatmap (Updated!)
A heatmap is basically a table that has colors in place of numbers. Colors correspond to the level of the measurement. Each column can be a different metric like above. It’s useful for finding highs and lows and sometimes, patterns.
From Nathan Yau | Visualize This
One of the problems when we have a big quantity of data is the correct way to visualize and offer to the reader a simple but general vision about all the information.
In order to visualize trends within large sets of data, it is useful consider to create a data heat map with color instead of a table with numbers.
And as everything in life, there ain’t no such thing as a free lunch, and is completely valid in this case: the accuracy is lost because we are replacing numbers for a range of colors, but in exchange we are obtaining a wide vision about trends.
The colors used within the heat map, belong a spectrum of colors based on its distance from the statistical mean, so, in that way, intuitively darker colors means one thing and lighter colors means another thing facilitating a quick evaluation about patterns, maximum and minimum values.
Updates (Sat 11/24/2018)
After some comments made by u/ELKronos and u/prv about how to improve this example, I added how the data looks like before and after tranformations.
Idea
Let’s use a heatmap in order to visualize the stats for America Soccer Cup since the beginning of the times (well, actually since 1916).
Data
In order to see what we are obtaining in exchange, let’s take a look to the table with the stats for America Soccer Cup
As you can see, it is extremely complicated achieves any conclusion easily.
Visualization
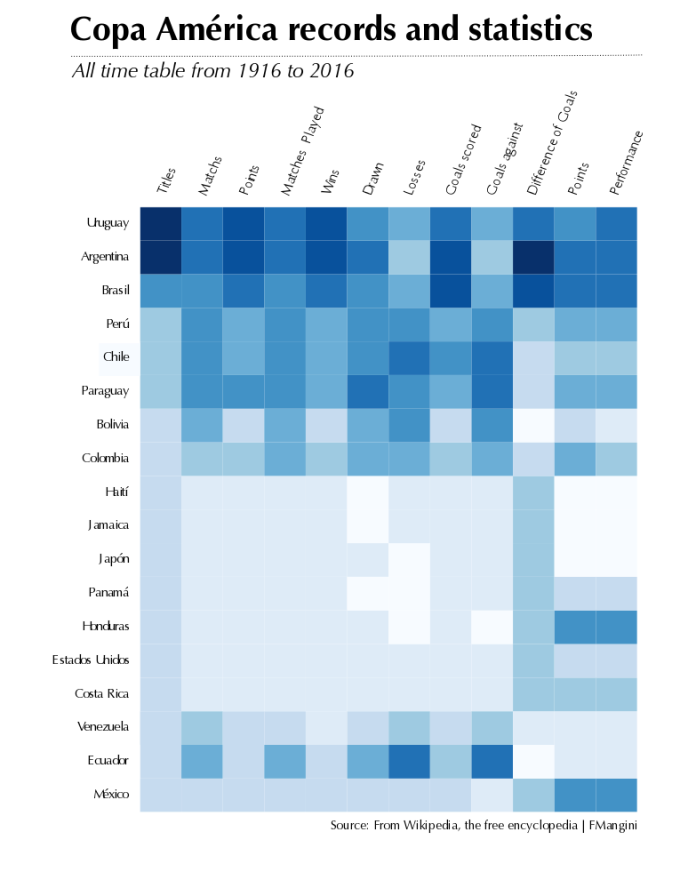
This is the visualization for the data about America Soccer Cup, and it is very simple to determinate which are the best team along the different tournaments, even when we lost accuracy for the lacks of numbers for each event.
Some ideas that we can elaborate after check this visualization:
- Argentina and Uruguay are the best team along all the tournaments.
- Argentina is the team with more power of goals and best difference of goals.
- Argentina, Brazil and Uruguay are the teams with best performance.
- There are three groups of countries with similar trajectories:
- Argentina and Uruguay
- Brazil, Peru, Chile, Paraguay, Bolivia and Colombia
- The rest of the teams with low performance since Bolivia to Mexico
Technical implementation
In order to facilitate the implementation for any heatmap, I am going to separate the code in different sections and elaborate an small explanation of each part, however if you want to see all the code and the dataset used in this example, check my github account.
1. Setup libraries
We will use two libraries, readr to read a csv file – the dataset – and RColorBrewer, to use the palettes of colors.
library(readr)
library(RColorBrewer)2. Get the data
The dataset is in my Github account because I prefer that my examples work out-of-the-box (if you copy, paste and execute the example, the code should work).
A second benefit of that is no matter what happen with the original dataset used in my example, I have it in your account.
# get data
url_soccer <- 'https://raw.githubusercontent.com/frm1789/soccer_ea/master/AmericaCupData.csv'
df_soccer <- read_csv(url(url_soccer))3. Order by
From all the data that we have, the most relevant is the quantity of titles that a team have. All the rest (goals, power of goals, won matches…) is subordinate to that.
# Order data for titles
df_soccer <- df_soccer[order(df_soccer$Titles, decreasing = FALSE),]
df_soccer <- data.frame(df_soccer)3. Transformations
One main point to consider, the function heatmap requieres a numerical matrix, for that reason we will work to delete the columns that we don’t need and transform the rest in numeric columns.
How the data is before transformation?
Validations before changes
All the rest of the data into the dataset is numeric or integer exceptPoints_1 andPerformance.
sapply(df_soccer, class)
(...)
# Points_1
# "character"
# Performance
# "character" Code for changes
# heatmap requieres a numerical matrix, for that reason we will move the names of the team as row.names
# and after that, we will delete the column "Team"
row.names(df_soccer) <- df_soccer$Team
df_soccer <- df_soccer[,-1]
# transformation to numeric for column "Points_1"
options(digits=2)
df_soccer$Points_1 <- sub(',', '.', df_soccer$Points_1)
df_soccer$Points_1 <- as.double(df_soccer$Points_1)
# transformation to numeric for column "Performance"
df_soccer$Performance = substr(df_soccer$Performance,1,nchar(df_soccer$Performance)-1)
df_soccer$Performance <- sub(',', '.', df_soccer$Performance)
df_soccer$Performance <- as.double(df_soccer$Performance)
df_soccer$Performance <- log(df_soccer$Performance)
# Dataframe to matrix
america_matrix <- data.matrix(df_soccer)How the data is after transformation?
Validations after changes
We can see that all the variables in our dataframe now are integer and after transformations, numeric.
sapply(df_soccer, class)
(...)
# Points_1
# "numeric"
# Performance
# "numeric" 4. Creating a heatmap
We are using the function heatmap almost out of the box, except the adding of margins and colors.
# Creation of heatmap
america_heatmap <- heatmap(america_matrix, Rowv=NA,
Colv=NA, col = brewer.pal(9, "Blues"), scale="column",
margins=c(2,6))